Research Topics
What is interrater and intrarater reliability? A quick guide.
What is interrater reliability, how is it different than intrarrater reliability, and which tests should we use to assess it?
Introduction
In any setting where people are making judgments, whether it's teachers grading essays, interviewers rating job candidates, or judges scoring a performance, consistency matters. If the same work receives drastically different evaluations depending on who’s assessing it, we begin to question the fairness and reliability of the process. This is where the concept of interrater reliability (IRR) comes in.
In this blog, we’ll break down what interrater reliability really means, why it’s so important, and how it differs from intrarater reliability. We’ll explore everyday, non-medical examples to make these concepts more relatable, and we’ll introduce key statistical tools like Cohen’s Kappa, Fleiss’ Kappa, and the Intraclass Correlation Coefficient (ICC) that help us measure how much agreement there really is between different raters. Whether you’re diving into research or just curious about how we define "fair" evaluation, let’s explore IRR.
What is Interrater Reliability?
IRR refers to the degree of agreement among two or more raters or observers evaluating the same phenomenon[1]. It is a critical measure that ensures assessments are consistent and not swayed by individual biases or subjective interpretations[2]. This is especially important in qualitative evaluations.
High IRR indicates that different evaluators are applying standards or criteria in a consistent way, which strengthens the credibility, validity, and generalizability of the results[3]. IRR plays a key role in fields such as research, education, hiring, and performance evaluations - anywhere subjective judgment is involved. For example, think of multiple judges scoring a figure skating routine, teachers grading student essays using a rubric, or interviewers rating candidates during a job interview. In each case, ensuring that all raters interpret and apply the criteria similarly is essential for fairness and accuracy.
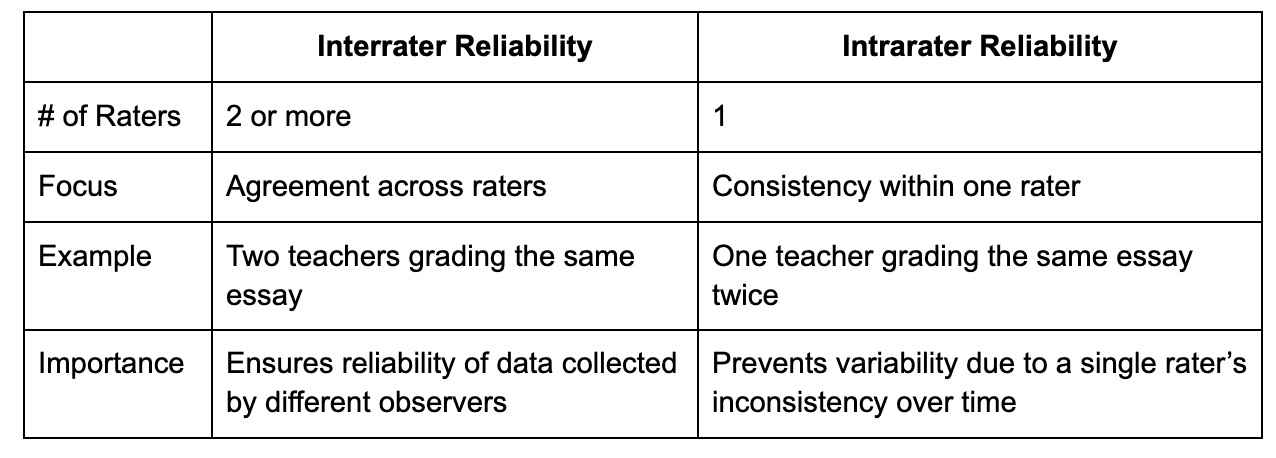
Interrater vs. Intrarater Reliability
Intrarater and interrater reliability are both essential measures of consistency in data collection, but they assess different aspects of agreement. Intrarater reliability evaluates whether a single rater can produce stable and repeatable results over time when assessing the same subject under consistent conditions[4]. This is important in contexts like clinical assessments where the same individual conducts repeated evaluations.
In contrast, interrater reliability measures the degree of agreement among multiple raters assessing the same subjects, ensuring results are not influenced by individual differences[5]. This is especially relevant in collaborative research or studies involving multiple evaluators. Together, these measures ensure data reliability and validity by minimizing bias and variability in both individual and group assessments.
Measuring Interrater Reliability
Several statistical methods are used to measure interrater reliability, depending on the type of data and number of raters.
- Cohen's Kappa is commonly used for two raters evaluating categorical data, accounting for chance agreement[6].
- Fleiss' Kappa extends this to multiple raters, making it ideal for group assessments of categorical data[7].
- The ICC is suitable for continuous or ordinal data and evaluates the variability of ratings across raters. ICC can be tailored to different study designs, with higher values indicating better reliability[8].
- Percentage Agreement is a simple but less robust method, as it doesn’t account for chance agreement.
To choose the right method, use Cohen’s Kappa for two raters, Fleiss’ Kappa for multiple raters, and ICC for continuous or ordinal data. Avoid relying solely on percentage agreement for more accurate results.
Cohen’s Kappa
Since Cohen’s Kappa is one of the most widely used measures for interrater reliability, let's dive a bit deeper into how it works. It specifically assesses the level of agreement between two raters while factoring in the possibility of agreement occurring by chance. This is important because it provides a more accurate picture of the true agreement between raters, beyond simple percentages of matching responses[9]. The formula for Cohen’s Kappa is:

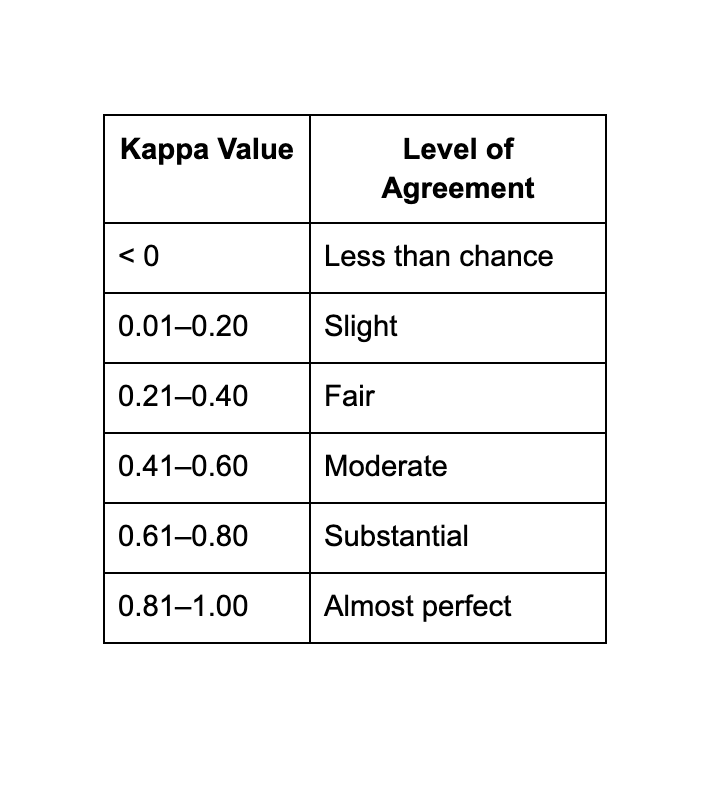
Where Po is the observed agreement between raters, and Pe is the expected agreement due to chance. Values range from -1 (indicating complete disagreement) to 1 (indicating perfect agreement), with 0 representing agreement purely by chance. Cohen’s Kappa is especially useful for categorical data and is commonly applied in research and clinical settings where precise evaluation and consistency are key.
The table below outlines the interpretation ranges for Cohen's Kappa, helping to assess the strength of agreement between raters based on the Kappa value.
Conclusion
In conclusion, IRR is a crucial measure of consistency in data collection, assessing the degree of agreement between multiple raters evaluating the same subjects. High IRR ensures fairness, validity, and reproducibility in research and assessments. While intrarater reliability focuses on the consistency of a single rater over time, IRR evaluates the alignment between different raters. Various statistical methods, such as Cohen’s Kappa, Fleiss’ Kappa, ICC, and percentage agreement, offer different ways to measure IRR based on the type of data and number of raters. Achieving high IRR is vital to ensuring that findings are not biased by individual perspectives, promoting more reliable and generalizable results across studies.
References
1. APA Dictionary of Psychology. https://dictionary.apa.org/interrater-reliability.
2. What is Inter-Rater Reliability? (Examples and Calculations). pareto.ai/blog/inter-rater-reliability
3. Fothergill, P. What is inter-rater reliability? Covidence https://www.covidence.org/blog/what-is-inter-rater-reliability/ (2024).
4. Gwet, K. L. Intrarater Reliability. in Wiley StatsRef: Statistics Reference Online (John Wiley & Sons, Ltd, 2014). doi:10.1002/9781118445112.stat06882.
5. Alavi, M., Biros, E. & Cleary, M. A primer of inter-rater reliability in clinical measurement studies: Pros and pitfalls. J. Clin. Nurs. 31, e39–e42 (2022).
6. McHugh, M. L. Interrater reliability: the kappa statistic. Biochem. Medica 22, 276–282 (2012).
7. Alexander. Fleiss’ Kappa. Statistics How To https://www.statisticshowto.com/fleiss-kappa/ (2016).

